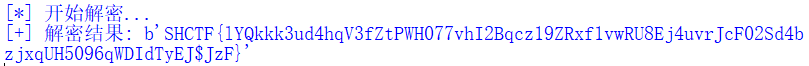import re from binascii import unhexlify from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes from cryptography.hazmat.primitives import padding
# 1) 从 data.txt 读 iv 和密文 withopen("data.txt", "r", encoding="utf-8") as f: lines = f.read().splitlines()
iv_hex = lines[0].split("=")[1].strip() cts = [re.search(r"\|\s*([0-9a-f]{32})\s*\|", ln).group(1) for ln in lines if ln.strip().startswith("|")]
defblocks8(b): return [int.from_bytes(b[i:i+8], 'big') for i inrange(0, len(b), 8)]
# 1) 恢复 x1..x6(keystream blocks) P_blocks = blocks8(P_known) C_blocks = blocks8(C_known) x = [p ^ c for p, c inzip(P_blocks, C_blocks)] # x1..x6
# 2) 恢复 m:m | (t_{i+2}*t_i - t_{i+1}^2),取 gcd t = [x[i+1] - x[i] for i inrange(len(x)-1)] u = [t[i+2]*t[i] - t[i+1]*t[i+1] for i inrange(len(t)-2)] m = reduce(math.gcd, [abs(ui) for ui in u])
# 3) 恢复 a,c num = (x[2] - x[1]) % m den = (x[1] - x[0]) % m a = (num * pow(den, -1, m)) % m c = (x[1] - a * x[0]) % m
# 4) 生成足够的 keystream 解密 C_flag need_blocks = math.ceil(len(C_flag) / 8) cur = x[-1] ks = [] for _ inrange(need_blocks): cur = (a * cur + c) % m ks.append(cur)
ks_bytes = b''.join(k.to_bytes(8, 'big') for k in ks)[:len(C_flag)] flag = bytes(cb ^ kb for cb, kb inzip(C_flag, ks_bytes)) print(flag.decode(errors="replace"))
flag = ''.join(chr(int(bits[i:i+7], 2)) for i inrange(0, (len(bits)//7)*7, 7)) print(flag)
flag:SHCTF{99f4a238-9bd5-498a-b8ea-5cd243a36a19}
题目6:阶段1-古典也颇有韵味啊
秘钥找个培根密码的在线网址解密得到:NOTVIGENERE(其中 U/V 合并)
然后自钥维吉尼亚解密得到:oops!you made it! here is your flag:shctf{cl@ssic_c2ypto_also_crypt0}
修改flag头:SHCTF{cl@ssic_c2ypto_also_crypt0}
import numpy as np from hashlib import md5 from Crypto.Cipher import AES from Crypto.Util.number import long_to_bytes import random import ast import sys
p1, p2, trace, result = None, None, None, None for line in lines: line = line.strip() ifnot line: continue if"="in line: k, v = line.split("=", 1) k, v = k.strip(), v.strip() # 使用 ast.literal_eval 安全解析列表,result 作为字符串直接读取 if k == "p1": p1 = ast.literal_eval(v) elif k == "p2": p2 = ast.literal_eval(v) elif k == "trace": trace = ast.literal_eval(v) elif k == "result": result = v
ifnot (p1 and p2 and trace and result): print("[!] Error: Failed to parse variables from data.txt") return
# --------------------------------------------------- # 第二步:利用侧信道泄露恢复 Key (GF(3) 高斯消元) # --------------------------------------------------- print("[-] Step 2: Recovering Key using Side-Channel Leakage...") equations = [] targets = [] # 筛选出 output=1 的方程: popcount(n & k) % 3 == 1 for n, b in trace: if b == 1: bits = [(n >> i) & 1for i inrange(128)] equations.append(bits) targets.append(1) # 取前 200 个方程构建矩阵 eq_count = min(len(equations), 200) M = np.array(equations[:eq_count], dtype=int) Y = np.array(targets[:eq_count], dtype=int) # 高斯消元求解 Ax = b mod 3 rows, cols = M.shape pivot_row = 0 aug = np.hstack((M, Y.reshape(-1, 1))) for j inrange(cols): if pivot_row >= rows: break candidates = np.where(aug[pivot_row:, j] % 3 != 0)[0] iflen(candidates) == 0: continue curr = candidates[0] + pivot_row aug[[pivot_row, curr]] = aug[[curr, pivot_row]] inv = 1if aug[pivot_row, j] % 3 == 1else2 aug[pivot_row] = (aug[pivot_row] * inv) % 3 for r inrange(rows): if r != pivot_row and aug[r, j] % 3 != 0: factor = aug[r, j] aug[r] = (aug[r] - factor * aug[pivot_row]) % 3 pivot_row += 1
key_val = 0 for j inrange(cols): for r inrange(rows): if aug[r, j] == 1and np.sum(aug[r, :j]) == 0: if aug[r, -1] == 1: key_val |= (1 << j) break print(f" [+] Recovered Key: {key_val}")
# 去除 Padding # Padding 是 0-255 的随机数,有效数据通常远大于 100000 # 我们找到第一个小于 300 的数作为截断点 enc_data = [] for val in v_out: if val > 300: # 阈值,区分 valid data 和 padding enc_data.append(val) else: break print(f" [+] Recovered encrypted data stream. Length: {len(enc_data)}")
# --------------------------------------------------- # 第五步:逆向 f1 (Seed爆破 + DFS 歧义消除) # --------------------------------------------------- print("[-] Step 5: Cracking f1 (Brute-force Seed & DFS)...") TARGET_PREFIX = b"SHCTF{"# 用于剪枝的已知前缀 correct_seed = None digit_choices = [] # 1. 寻找正确的 Seed # 遍历 100000 - 999999 for seed inrange(100000, 1000000): random.seed(seed) last = 0 possible = True current_choices_list = [] for val in enc_data: target = val ^ last last = val r = random.randint(100000, 999999) opts = [] # 偶数规则: d + r = target for d inrange(0, 10, 2): if d + r == target: opts.append(d) # 奇数规则: d * r = target for d inrange(1, 10, 2): if d * r == target: opts.append(d) ifnot opts: possible = False break # 去重并排序 current_choices_list.append(sorted(list(set(opts)))) if possible: correct_seed = seed digit_choices = current_choices_list print(f" [+] Found valid Seed: {seed}") break if correct_seed isNone: print("[!] Failed to find seed. Check padding logic.") return
# DFS 函数 defcheck_solution(digits): """将数字列表转为 Flag 字符串并检查前缀""" s = "".join(str(d) for d in digits) try: b = long_to_bytes(int(s)) # 检查前缀 iflen(b) >= len(TARGET_PREFIX): ifnot b.startswith(TARGET_PREFIX): returnFalse # 检查完整性 (如果长度不够长,只要前缀对就可以继续) # 但这里我们是在最后一步检查 return b except: returnFalse
# 终止条件 if idx == len(digit_choices): s = "".join(str(d) for d in current_digits) try: final_bytes = long_to_bytes(int(s)) if final_bytes.startswith(TARGET_PREFIX) and final_bytes.endswith(b"}"): return final_bytes except: pass returnNone
# 递归搜索 for digit in digit_choices[idx]: current_digits.append(digit) res = dfs(idx + 1, current_digits) if res: return res current_digits.pop() returnNone
# 执行搜索 # 为了避免递归深度过深(虽然这里只有几百层,Python默认1000,通常没问题),可以设置一下 sys.setrecursionlimit(5000) flag = dfs(0, []) if flag: print("\n" + "="*40) print(f" SUCCESS! Flag Found: \n {flag.decode()}") print("="*40) else: print("\n[!] DFS finished but no flag found. Review constraints.")
import ast from Crypto.Util.number import long_to_bytes
# 1. 读取数据 # 请确保 data.txt 在同一目录下 withopen('data.txt', 'r') as f: p = int(f.readline().strip()) h = ast.literal_eval(f.readline().strip())
# 过滤掉 h 中的方括号标记 (如果有的话,根据你提供的文件内容样例) # 假设 h 是一个纯整数列表,如果 data.txt 格式复杂,请自行调整解析 # 这里假设 h 已经是一个 list of integers
n = 70 m = len(h) print(f"[*] Parameters: n={n}, m={m}") print(f"[*] Modulus p (approx {p.bit_length()} bits)")
# 2. 构建正交格 (Orthogonal Lattice) # 我们寻找向量 u 使得 u * h = 0 mod p # 构造格基矩阵 B (m x m): # [ 1 0 ... -h_0 * h_{m-1}^-1 ] # [ 0 1 ... -h_1 * h_{m-1}^-1 ] # ... # [ 0 0 ... p ]
# 确保 h 的最后一个元素可逆(p是质数,只要不为0即可) # 如果 h[-1] 为 0,通常交换位置即可,但为了保持顺序对应,这里假设题目生成的随机数不为0 if h[-1] % p == 0: raise ValueError("h[-1] is 0 mod p, need to swap specific columns.")
h_last_inv = inverse_mod(h[-1], p)
# 初始化单位阵 M = Matrix(ZZ, m, m) for i inrange(m - 1): M[i, i] = 1 M[i, m - 1] = (-h[i] * h_last_inv) % p M[m - 1, m - 1] = p
print("[*] Running LLL on orthogonal lattice (this may take a minute)...") L = M.LLL()
# 3. 利用正交性恢复 A 的行空间 # 理论上,L 中的短向量 u 都满足 u * A^T = 0 # 我们取前 m-n 个最短的向量构成矩阵 U # A 的行向量应该在 U 的右核 (Right Kernel) 中
print("[*] Computing kernel...") # 取足够多的约束向量。理论上 rank(A) = n,所以我们需要 m-n 个正交约束 U = L[0 : m - n] Kernel = U.right_kernel()
print("[*] Running LLL on Kernel basis to recover rows of A...") # Kernel 的基包含了 A 的行向量。A 的行向量很短 (0,1,2),所以 LLL 应该能把它们找出来 Recovered_Basis = Kernel.basis_matrix().LLL()
# 4. 寻找 Flag # flag 对应的行只包含 0 和 1 (或者全为 0 和 -1,因为基向量符号不确定) print("[*] Searching for flag candidate...")
found = False for row in Recovered_Basis: vec = list(row) # 检查是否只由 0, 1 组成 ifall(x in [0, 1] for x in vec): bits = "".join(str(x) for x in vec) # 转为 bytes try: flag_int = int(bits, 2) flag = long_to_bytes(flag_int) ifb'SHCTF{'in flag: print(f"\n[SUCCESS] Flag found: {flag.decode()}") found = True break except: continue # 检查是否只由 0, -1 组成 (LLL 可能会翻转符号) elifall(x in [0, -1] for x in vec): bits = "".join(str(-x) for x in vec) try: flag_int = int(bits, 2) flag = long_to_bytes(flag_int) ifb'SHCTF{'in flag: print(f"\n[SUCCESS] Flag found: {flag.decode()}") found = True break except: continue
ifnot found: print("[-] Flag row not found immediately. Check the recovered basis manually or parameters.") # 打印一些只有少量非0/1元素的行作为调试 for i, row inenumerate(Recovered_Basis): vec = list(row) # 简单统计非 0/1/-1 的元素个数 weird_counts = sum(1for x in vec if x notin [0, 1, -1]) if weird_counts == 0: print(f"Row {i} looks binary: {vec[:20]}...")